《Streaming Systems》第三章 水位线
到目前为止,我们是从用户或数据科学家的角度来看待流式系统的。在这一章,我们会从流式系统底层实现的角度来看待同样的问题。我们会讨论水位线如何在数据到达时创建、怎样在数据处理的 pipeline 中传播,以及怎样影响着输出的时间戳。
定义
考虑任意一个持续获取数据并产生输出的 pipeline,我们希望解决的问题是:何时可以认为关闭一个事件时间窗口是安全的?
一个很自然的想法是简单地根据当前的处理时间。但第一章中已经提到,数据处理和传输并不是瞬间完成的,处理时间和事件时间之间存在偏差,任何 pipeline 中出现的一些细微影响都可能导致数据被分配到错误的窗口中。我们无法对窗口做出任何保证。
另一个直观但并不正确的方法是考虑 pipeline 处理数据的速率。速率会随着输入、可用资源等属性的变化而变化,并且也并不能回答关于完整性的问题。速率指标可能可以用于检测处理过程中出现的一系列暂时性的问题(宕机、网络错误等)或持久性的问题(需要修改逻辑的应用层错误以及人为干预等),但它并不能告诉我们哪怕是任意一条数据是否已经被 pipeline 所处理,这显然不能保证输出的正确性。
为了得到一个更为可靠的度量过程的方法,我们对流式数据做出如下基本假设:所有数据都有一个与之关联的逻辑上的事件时间戳。在某些情况下,我们可以将事件最初发生时的时间作为逻辑上的事件时间戳。接下来我们就可以考虑这样的时间戳在 pipeline 中的分布。在 pipeline 中,正在被处理的数据时间戳会形成一个如下图所示的分布:
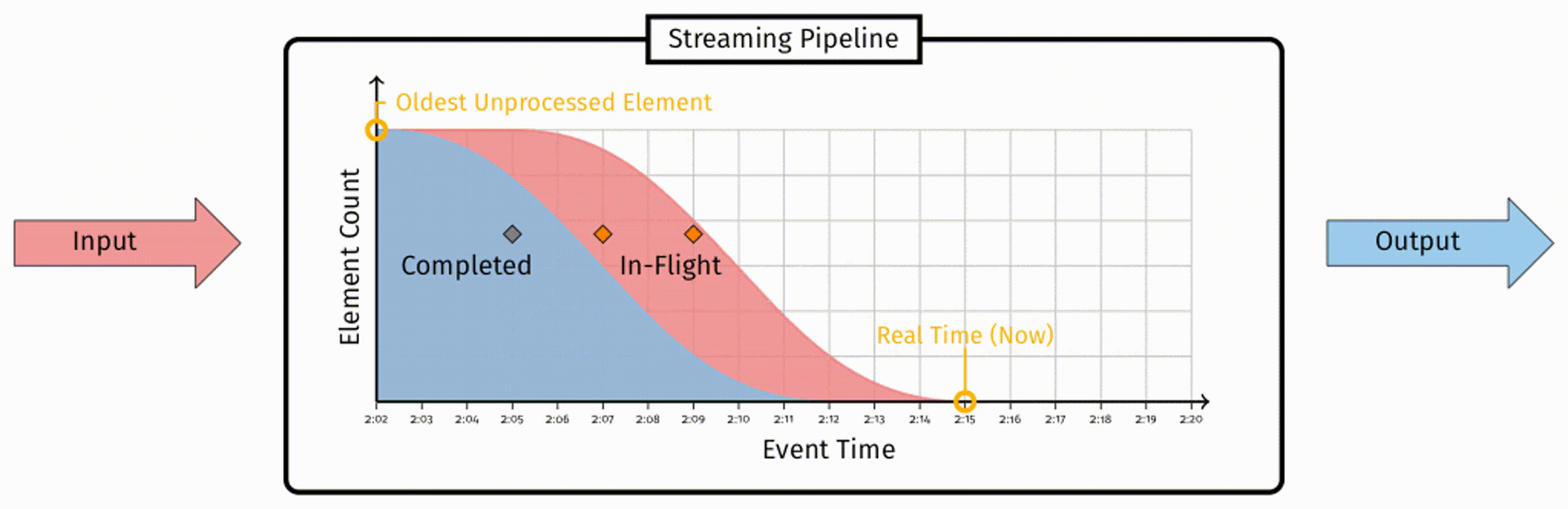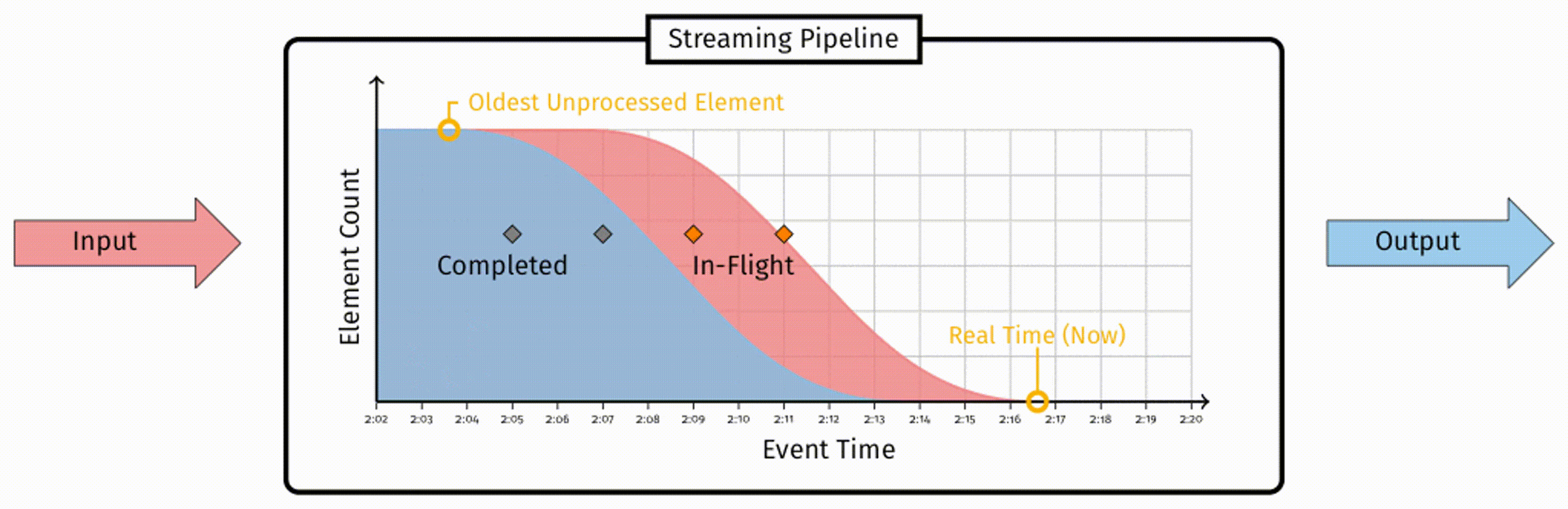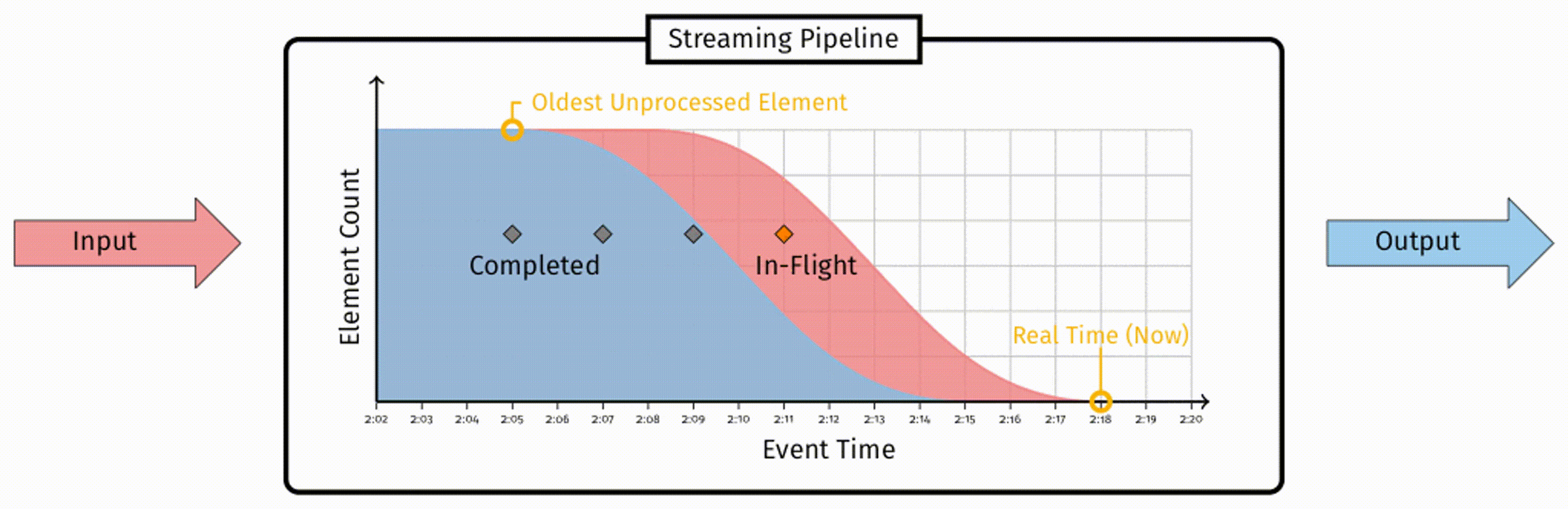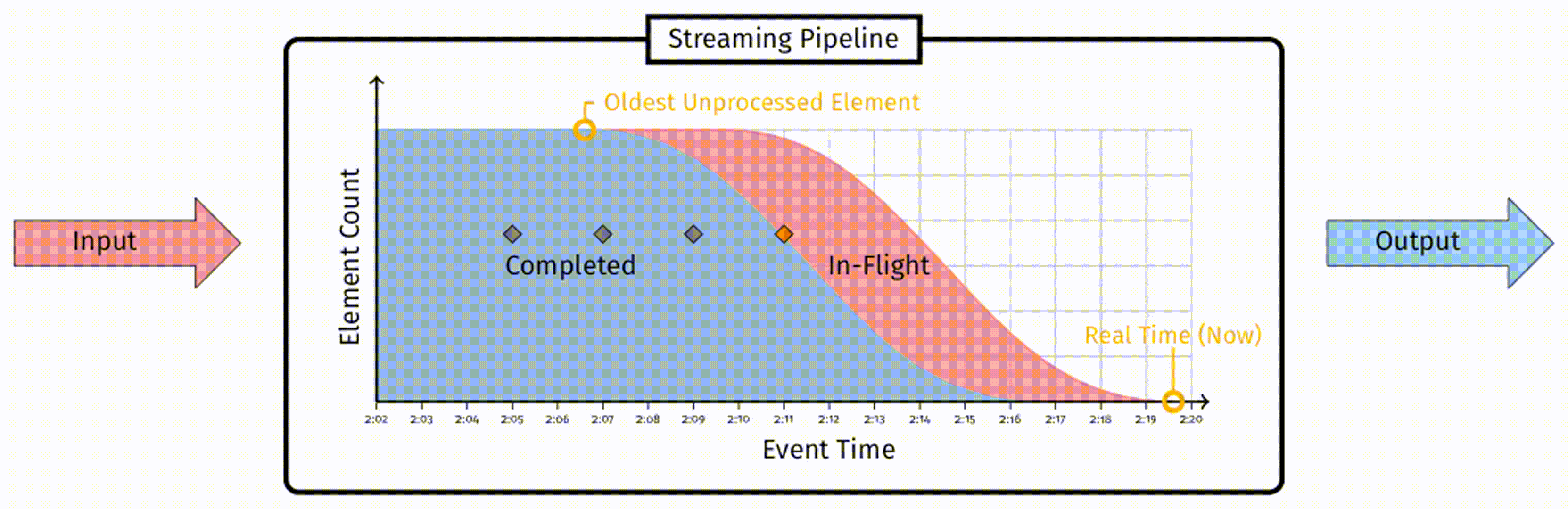
数据会被输入到 pipeline 中,经过处理,最终被标记为已完成。任何一条数据,要么是 ”in-flight“ 状态,即被接收到但尚未处理,要么是 ”completed“ 状态,即这条数据不再需要任何处理操作。参考该图,如果从事件时间的角度考虑数据的分布,随着时间推移,新的数据会从右侧加入到 ”in-flight“ 部分,越来越多的数据会被从 ”in-flight“ 部分移动到 ”completed“ 部分。
在这个分布中关键的一点在于,”in-flight“ 部分最左侧,表示着 pipleline 中尚未被处理的最早的事件时间戳。我们用这个值来定义水位线:
水位线是单调递增的尚未完成工作的最早时间戳。
注意这里提到了单调性,目前的讨论还没有涉及到这一点。如果我们只考虑最早的未完成事件时间,那么水位线并不总是单调的,因为我们没有对输入数据做出任何假设。我们会在之后讨论这一问题。
这个定义提供了两个有用的基本属性:
- 完整性
如果水位线超过了时间戳 $T$,根据单调性,可以保证不需要为在 $T$ 或之前及时到达的数据(非迟到数据)做出任何额外处理。因此,我们可以正确地发出 $T$ 之前的聚合计算结果。 - 可见性
如果有数据在 pipeline 中被卡住了,水位线就不会前进。更进一步,我们可以通过检查阻止水位线前进的数据来找到问题原因。
在数据源创建水位线
第二章中提到,所有水位线都可以被分为两大类:完美水位线 和 启发式水位线,回顾第二章中这两种水位线的对比:
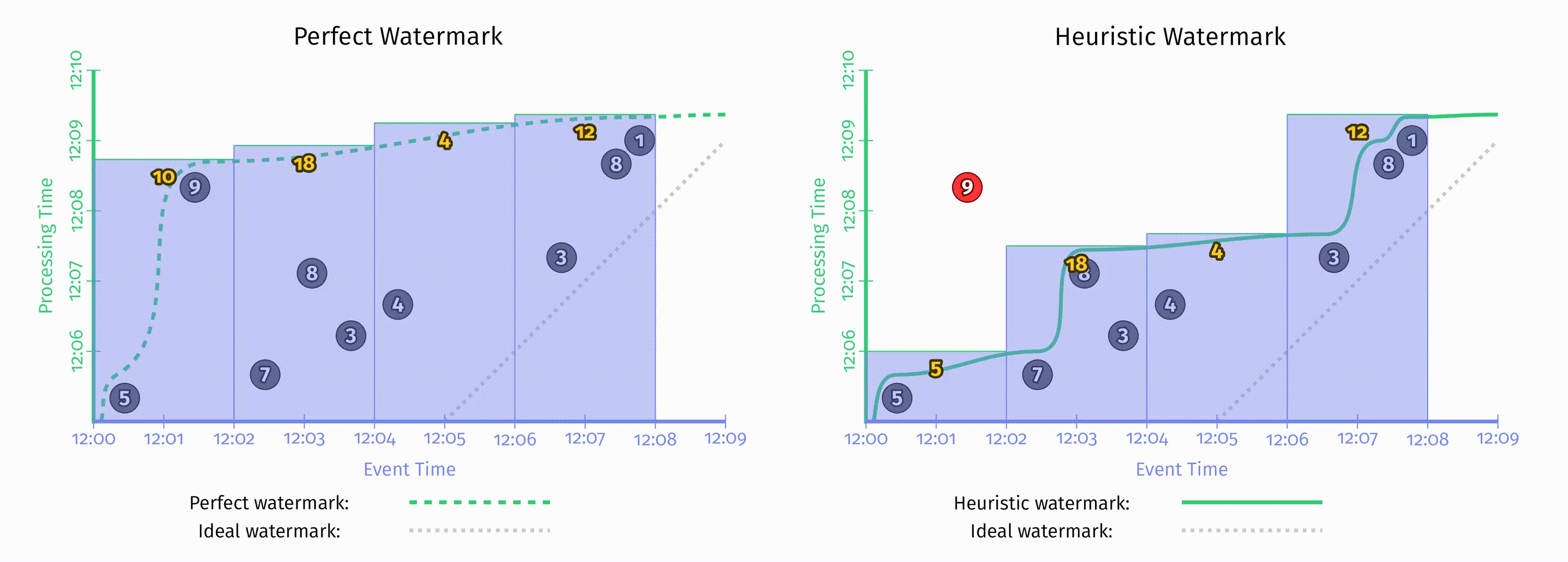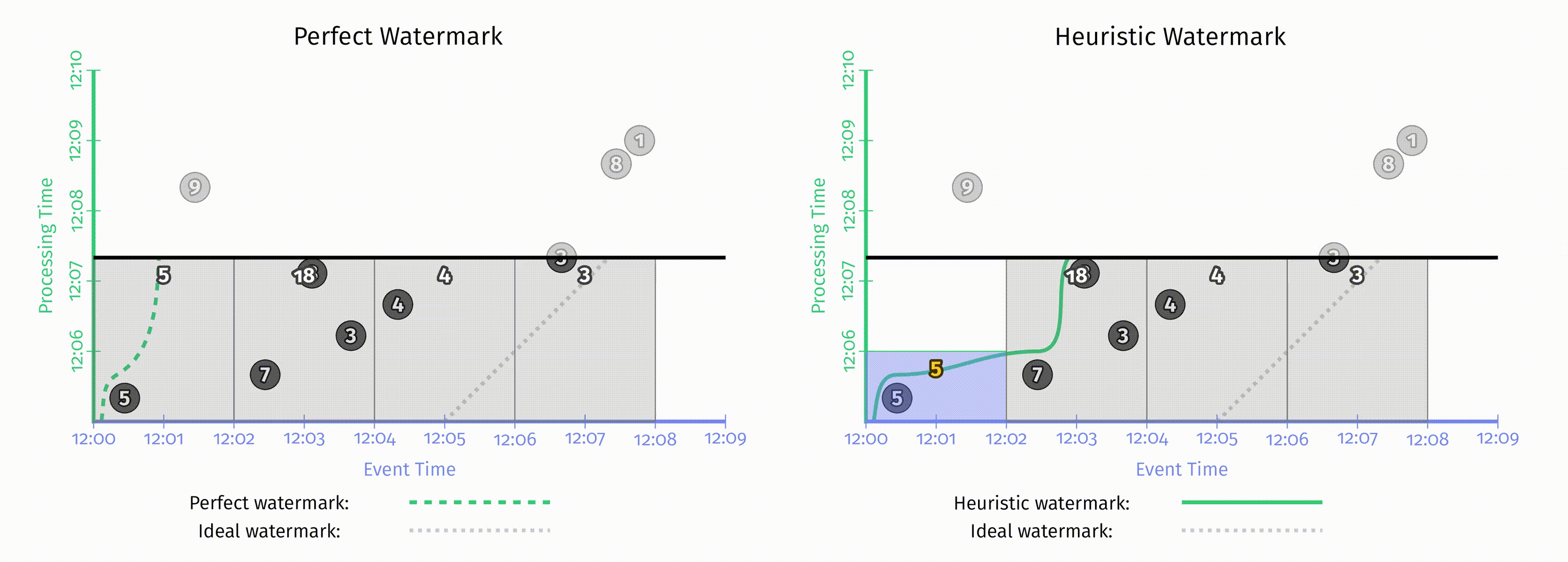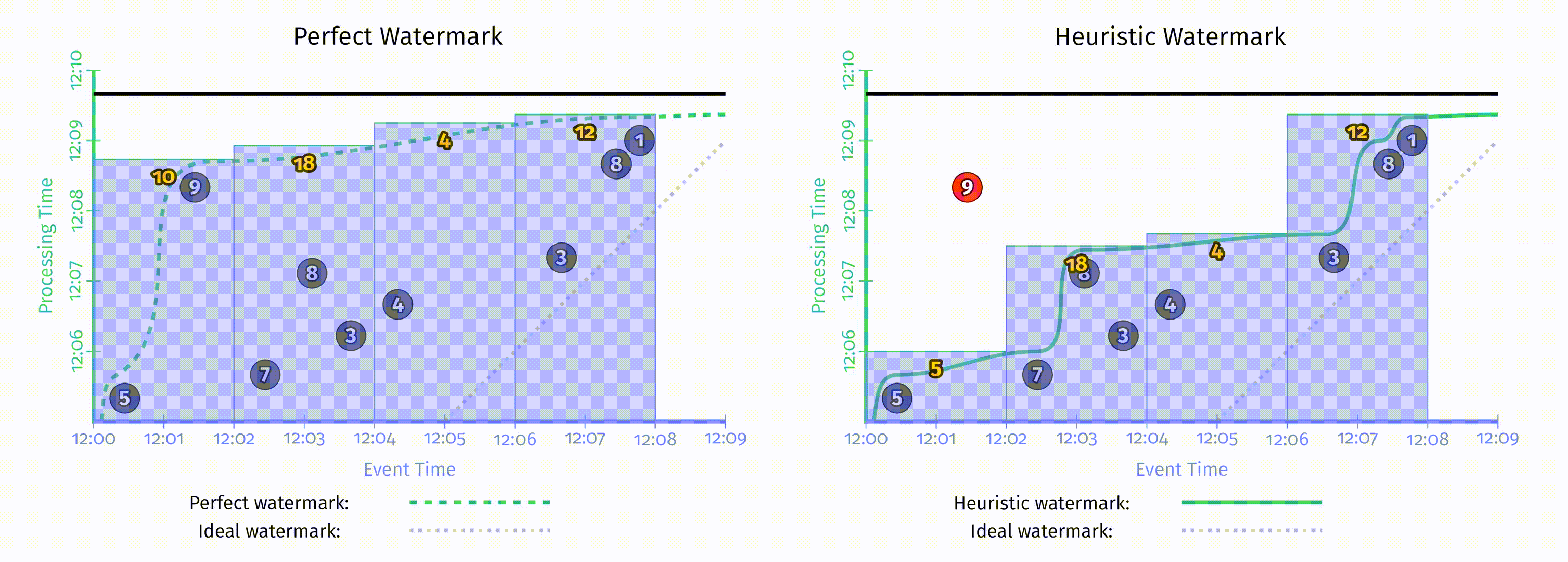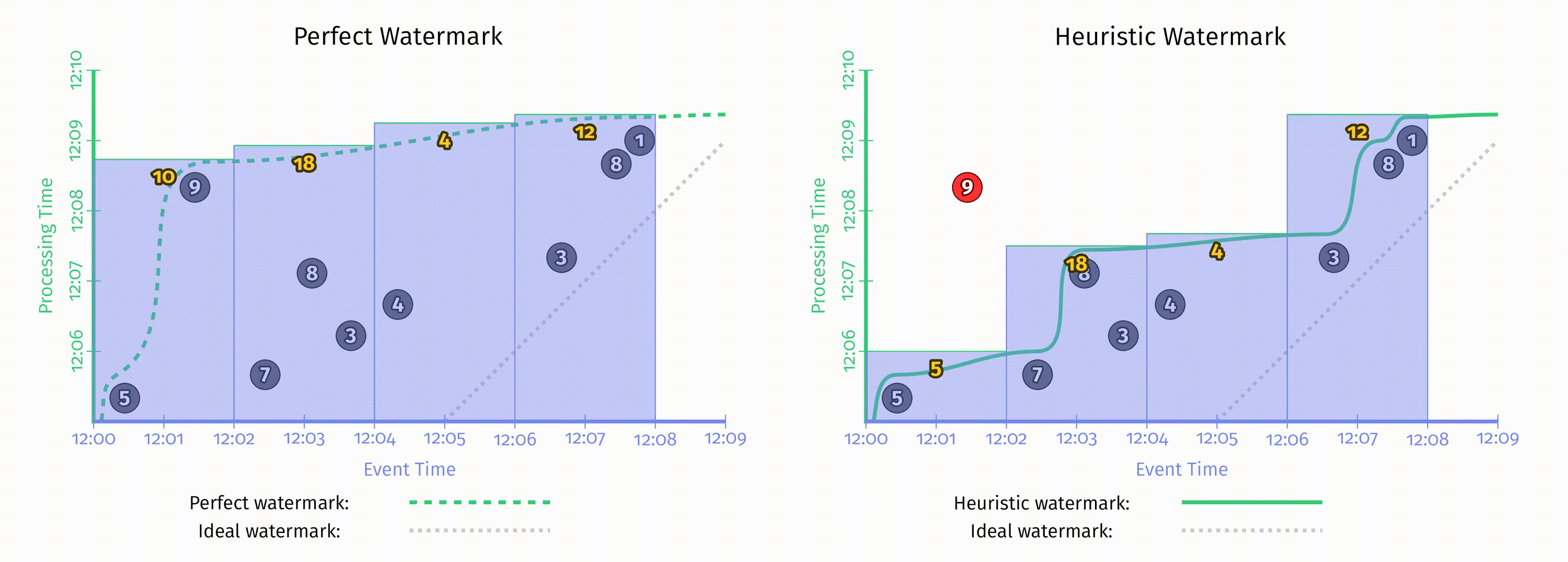
不管是完美的还是启发式的,水位线创建后其类型便不再变化。至于应该创建完美的还是启发式的水位线,这很大程度上取决于消费的数据源的性质。
完美水位线的创建
完美水位线提供了严格保证:事件时间在水位线之前的数据不可能再出现。使用完美水位线的 pipeline 不需要处理迟到数据。对于现实世界中大多分布式数据源,实现完美水位线并不现实。以下是几个可以创建完美水位线的例子:
- 进入时间戳
一个将数据进入系统的时间戳记为事件时间的数据源可以创建完美水位线,数据源只是简单地跟踪系统发现数据时的当前处理时间。这也是2016年之前几乎所有支持窗口的流式系统所使用的方法。
因为事件时间(实际上是处理时间)在单一数据源上是单调递增的,所以系统对后续的输入数据有着完备的认识。因此,事件时间的过程和窗口语义很容易推理和实现。但其缺点在于,水位线和数据自身的事件时间并无关联。 - 时序日志的静态集合
一个规模不变且按时序排序的日志数据源(比如 Apache Kafka 中有着静态分区的 topic,每个分区中的事件时间是单调递增的)可以在其上创建完美水位线。数据源只需要跟踪所有静态分区集合中未处理数据的最小事件时间即可,也就是每个分区中最近一条读到的记录中的最小事件时间。
与进入时间戳类似,由于静态分区集合中的事件时间是单调递增的,所以系统对即将到来的时间戳有着完美的认知。这实际上是有界无序数据处理的一种形式,集合中跨已知分区所带来的无序性会被所有分区中已观察到的最小事件时间所限制。准确地说,与其说日志数量需要是静态的,不如说是系统事先知道任何给定时刻的日志数量。一个更为复杂的数据源可能由动态选择的输入日志组成,比如 Pravega,但这也可以构造出完美水位线。只有当任意给定时刻动态集合中的日志数量不确定时(下一节中的例子),才需要退而求其次使用启发式水位线。
通常来说,能够保证分区中的时间戳单调递增的唯一方法是当数据写入到分区时分配时间戳。比如 web 前端将日志事件直接写入 Kafka。尽管这样的场景也是有一定限制的,但这显然比用进入数据处理系统的时间戳作为事件时间有用很多,因为水位线此时能够跟踪数据中有意义的真实事件时间。
启发式水位线的创建
启发式水位线仅仅提供这样一种 预测:事件时间小于水位线的数据不会再出现。使用启发式水位线的 pipeline 可能需要想办法处理 迟到数据。如果启发式水位线构造合理,迟到数据会非常少,但如果系统希望支持需要正确性的用户场景,它需要为用户提供处理迟到数据的方法。
对现实世界中大多数分布式输入数据源,构造完美水位线从计算或操作上来说是不现实的,但我们可以利用输入源的特征构建一个具有高准确度的启发式水位线。以下是两个启发式水位线的例子:
- 时序日志的动态集合
考虑一个由结构化日志文件组成的动态集合(每个单独的文件中包含事件时间单调递增的日志记录但不同文件之间的事件时间没有关联),完整的日志文件(即 Kafka 中的分区)集合在运行时不可知。这样的输入在由多个独立团队构建且管理的全局服务中很常见。这种情况下很难创建完美水位线。
即便在不知道输入的全部信息的情况下,通过跟踪集合中未处理数据的最小事件时间、管理增长率以及利用诸如网络拓扑和带宽等外部信息,依然可以创建一个非常精确的水位线。 - Google Cloud Pub/Sub
Pub/Sub目前不保证有序交付,即便一个单独的publisher按序发布两条信息,仍然有很小的概率在交付时出现乱序(这是由底层架构的动态本质决定的,该架构可以在没有用户干预的情况下面对高吞吐量时进行扩容),因此,无法对Cloud Pub/Sub创建完美水位线。但Cloud Dataflow团队依然利用Cloub Pub/Sub中的可用信息构建了合理且精确的启发式水位线。
考虑用户玩手机游戏的场景,他们的得分会发送到pipeline进行处理,大致可以认为,对任意作为输入的手机设备,提供完美水位线是不可能的。因为设备可能在一段时间内离线,因此无法提供任何对输入完整性的评估。但是可以为在线设备的输入完整性构造水位线,从提供低延迟结果的角度看,在线用户是最为重要的,因此这样做并不是一个很大的缺点。
对启发式水位线,一般来说,对数据源信息了解越多,启发式方法就可以越好,迟到数据也会越少。考虑到数据源类型、事件分布、用例都会有很大不同,因此没有一种能够适用于所有情况的解决方法。但无论是完美水位线还是启发式水位线,在数据源创建水位线后,系统可以在 pipeline 中传播水位线,完美水位线在下游仍然是完美的,启发式水位线也依然是启发式的。水位线的好处在于:可以将在 pipeline 中追踪完整性的复杂问题缩小到在数据源创建水位线的问题。
水位线传播
理解水位线传播
水位线传播和输出时间戳
窗口重叠的情形
百分位水位线
处理时间水位线
《Streaming Systems》第三章 水位线
http://huangxiao.info/2021/12/11/streaming-systems-chapter3/